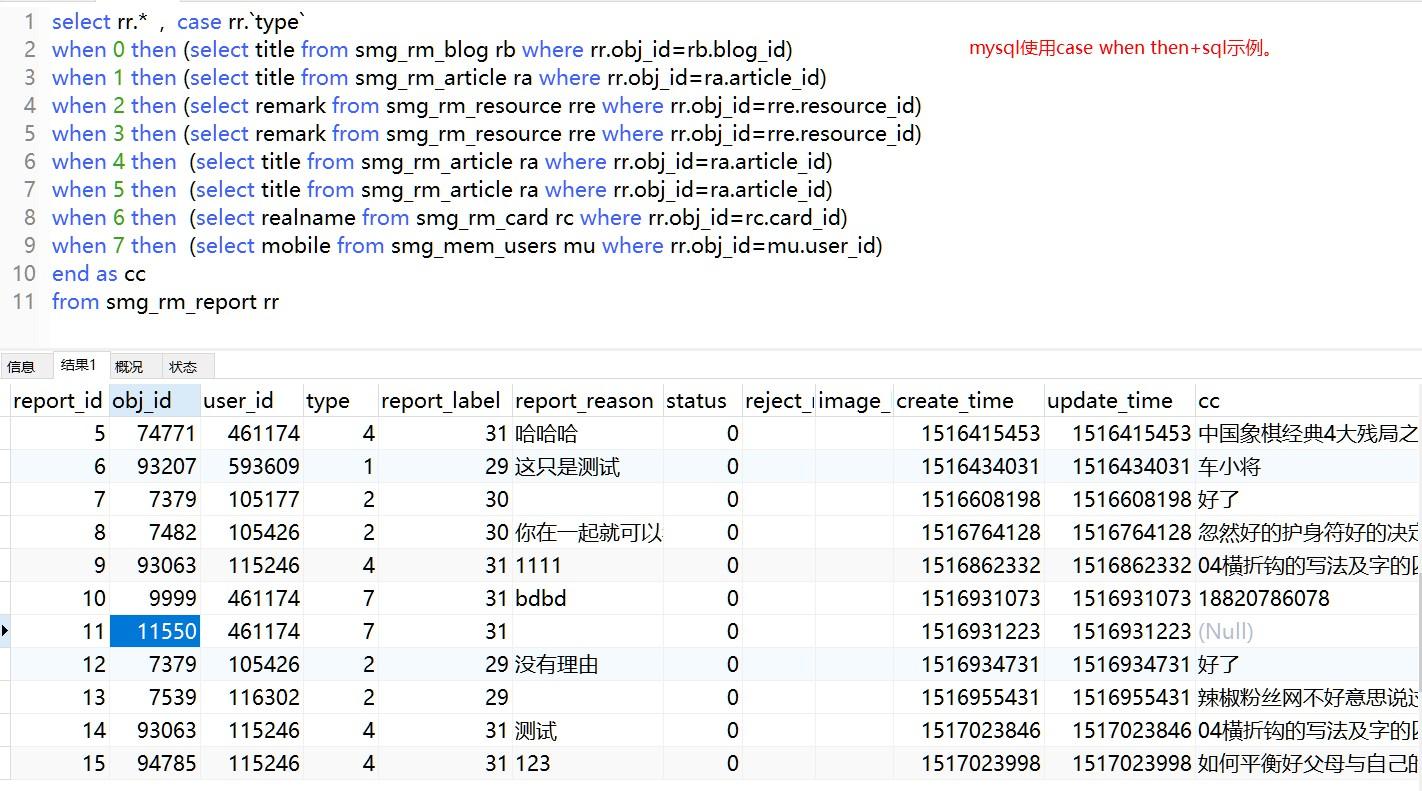
经典SQL语句
17、mysql给select结果加一个序号
SELECT @row := @row +1 AS ROWID, login_type, COUNT(*) AS con FROM userlog, (SELECT @row := 0) r where logintime BETWEEN 1410364800 AND 1410451200
16、统计商品表中各个分类总有多少记录
select cate_id,count(id) from goods where isshow=1 group by cate_id
15、mysql查找某个字符串出现多次的方法
select * from all_email where email regexp '(.*@){2}'
14、mysql查询及删除重复记录的方法
查找表中多余的重复记录,重复记录是根据单个字段(email)来判断:
select * from email1 where email in
(select email from email1 group by email having count(email) > 1)
这个语句在网上某专家网站上能找到原型,可以直接告诉你,效率好差劲,在我这里跑不动。
select * from email1 where length(sname) > 7 and length(sname) <= 9 group by email having count(`email`)>1
就是这样的语句也要跑十几秒。
在删除重复数据的时候,在网上找了好多,但多数都不管用,在我的数据库中,真实不重复数据可能是35W左右,也就是说还有1W的重复数据,重复次数不等。如果想一次列出来重复的数据,速度异常的慢。几十万数据要整理到什么时候呀。于是就想到了一个折中的办法,distinct,知道了吧,直接将不重复的数据写到新表里,立马不就效果出来了:
insert into email2(email, id, sname) select distinct(email),id, sname from email1,你觉得这个语句能按照你的想象得到新表不重复数据吗??留给你试验。
insert into email2 select * from email1 group by email having count(*)>=1
这样1分钟多点,不重复的数据全到了email2表中,来个重命名表名不就行了。鄙视网上所谓的专家,不测试直接发到网上。
PS:如果不嫌麻烦,也可以用select id, email, count(*) as c from email2 where length(sname) > 7 and length(sname) <= 9 group by email having count(`email`)>1 order by c desc来查一下,最大重复的有多少个,然后慢慢删除,具体语句还没有想起来 -_-
13、将文章表里的文章总数更新到分类统计字段中
update category set totalurl= (select count(id) from article where article.pid=category.id and article.isclose=0) ;
12、mysql导出查询的数据为csv格式
select * from t_gupiao_code where f_bankuai_id=0 and f_name is not null order by f_code into outfile 'c:/a.csv' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY '\n'
11、查找表中不连续的ID且大于156
select * from (select uid from pre_common_member order by uid desc) t
where not exists (select 1 from pre_common_member where uid=t.uid-1) and uid>156
10、查询每个分类的最新五条文章
select t.* from article t where t.id in
(select id from article where tid=t.tid order by addtime desc limit 5) order by t.tid desc, t.addtime desc
查询每个分类的最新一条文章:
select * from (select id,cate_id, title from article where cate_id > 154 order by id desc) as tt group by tt.cate_id
9、mysql生成300到500随机数
select floor(300+rand()*500);
8、将第二天的price更新到前一天去
update t_ a left join t_ b on a.f_gupiao_id=b.f_gupiao_id and a.f_gupiao_closed_time=b.f_gupiao_closed_time-86400 set a.f_yesterday_closed_price= b.f_yesterday_closed_price;
7、mysql 从 表 A 中往 表 B 中插入在表B中不存在且“不固定字段”记录集 的语法
INSERT INTO 表B SELECT NULL as id, uname,passwd,'2' as u_type,ids as id,'1' as status FROM 表A WHERE NOT EXISTS (SELECT 1 FROM 表B WHERE 表B.id = 表A.id AND 表B.u_type=2)
6、mysql 统计某字段重复数并统计重复总记录数
SELECT COUNT(*),字段一 FROM 表A GROUP BY 字段一 HAVING COUNT(字段一)>1;
5、同一个表中重复数据的最大值
现在我有一张表
name grade
张三 80
张三 79
张三 81
李四 89
李四 92
需要查询张三、李四的最大分数
方法一:
select * from tb as a where not exists(select 1 from tb name=a.name and grade>a.grade)
方法二:
select a.* from tb a join (select MAX(grade) AS grade,name from tb group by name) b on a.name=b.name and a.grade=b.grade
4、汇总一年中各个月分的信息
select distinct(substr(f_date,1,7)) as cc, count(*) dd from t_abc group by cc order by cc desc
3。在同一表中取出ID和 ID-1 的记录
假设ID唯一
select * from tt where f_type=1 and f_name like '%京东广告%'
union all
select a.* from tt a inner join (
select * from tt where f_type=1 and f_name like '%京东广告%') b
on a.id=b.id-1
select * into jmdcw in \'D:\\php\\Apache2.2\\htdocs\\asp\' \'excel 4.0;\' from A order by ID
select * into B from A where 1<>1 (不能复制主键、索引、约束) | 

 发表于 2024-1-24 11:30
发表于 2024-1-24 11:30